MySQL Cluster 7.2 GA Released, Delivers 1 BILLION Queries per Minute
70x Higher JOIN Performance, NoSQL Key-Value API & Cross Data Center Sharding with Replication
Oracle is delighted to announce the immediate availability of the production-ready, GA release of MySQL Cluster 7.2, available for download under the GPL, and as part of the commercial MySQL Cluster Carrier Grade Edition, including management tools, product certifications and 24x7 global support.
New benchmarks demonstrate MySQL Cluster's ability to support the most demanding web and telecoms workloads, while maintaining 99.999% availability. MySQL Cluster delivered 1 billion queries per minute (17.6 million queries per second), scaled-out across 8 x commodity Intel x86 server nodes, accessed by the NoSQL C++ NDB API.
To demonstrate native write-scalability with its auto-sharded, multi-master architecture, MySQL Cluster delivered almost 110 million UPDATEs per minute (1.8m per second) across the same cluster, without the complexity of developers having to manually shard (partition) their database at the application level.
MySQL Cluster achieved this level of throughput without sacrificing consistency or redundancy - all updates were synchronously replicated between data nodes, ensuring the cluster maintains 99.999% availability with no data loss in the event of outages or planned maintenance activities.
Of course MySQL Cluster also delivers the rich functionality of SQL and all the data integrity you'd expect from an ACID-compliant relational database, enabling users to perform complex, real-time queries against their OLTP data sets (which themselves are much faster in the 7.2 release), as well as optimized key-value operations.
You can read more about the benchmark in the blog post: 1 Billion queries per minute using MySQL Cluster 7.2
New Feature Summary
The MySQL Cluster 7.2 GA release builds upon the Development Milestones published over the past 9 months, which provided the community with an opportunity to test and provide feedback on the latest features.
MySQL Cluster 7.2 offers a range of new capabilities designed to enable the delivery of next generation web services, enhance cross data center scalability and improve ease-of-use, whether deployed on-premise or in the cloud:
Enabling next generation web services:
- 70x higher complex query performance
- Native Memcached API
- 4x higher data node scalability
- Integration with the latest MySQL 5.5 server
- Support for Virtual Machine (VM) environments;
Enhancing cross data scalability:
- New multi-site clustering with auto-sharding and synchronous replication between datacenters
- Improved active/active replication between data centers with eventual consistency
Improved Ease-of-Use:
- Consolidated user privileges
- MySQL Cluster Manager 1.1.4.
Example use-cases benefiting from MySQL Cluster 7.2 include:
- High volume OLTP
- Real time analytics
- Ecommerce and financial trading with fraud detection
- Mobile and micro-payments
- Session management & caching
- Feed streaming, analysis and recommendations
- Content management and delivery
- Massively Multiplayer Online Games
- Communications and presence services
- Subscriber / user profile management and entitlements
- Service Delivery Platforms
- IMS (IP Multimedia Subsystem) services
- VoIP, IPTV and Video-on-Demand
Download the whitepaper for details of the implementation and use of the new features in MySQL Cluster 7.2.
Those new features are also summarized below.
70x Higher JOIN Performance with Adaptive Query Localization
For many years, MySQL has delivered the benefits promised by NoSQL data stores (simple APIs, real-time latency, auto-sharding for linear scalability across commodity hardware, on-line operations and High Availability) together with the reassurance of ACID transactions and the flexibility of an SQL interface. In MySQL Cluster 7.2, the SQL interface is optimized to massively improve the speed of large, complex JOIN operations that span multiple partitions (shards).
By default, JOINs are executed in the MySQL Server, which provides high performance when the data is local. In MySQL Cluster, the data is distributed across multiple, redundant data nodes that are external to the MySQL Servers. As a consequence, the nested-loop-join in the MySQL Server needs to access the data nodes repeatedly at each step. As the depth of the JOIN or the size of the intermediate result sets grow, the number of messages to the data nodes increases quickly, which can dramatically slow down query execution.
The Adaptive Query Localization (AQL) functionality ships queries from the MySQL Server to the data nodes where the query executes on local copies of the data in parallel, and then returns the merged result set back to the MySQL Server, significantly speeding up the query.
A new Index Statistics function enables the SQL optimizer to build a better execution plan for each query. In the past, altering a non-optimal query plans required the manual enforcement of indexes via USE INDEX or FORCE INDEX. To get maximum benefit from AQL, it is strongly recommended to run the ANALYZE_TABLE command before the table is queried for the first time.
You can learn more about AQL from the MySQL Cluster 7.2 New Features whitepaper.
Testing on a real world query from a MySQL Cluster user in a web-based Content Management System delivered orders of magnitude higher performance using AQL.
- The application filtered content assets against device capabilities and user entitlements across 11 tables with a total of 33,500 rows, returning a result set of just over 2,000 rows and 19 columns per row.
- AQL reduced the query execution time from a horrible 87.23 seconds to a much happier 1.26 seconds!
- You can read more about the testing behind this query in the blog post:70x Faster Joins with AQL in MySQL Cluster 7.2 DMR
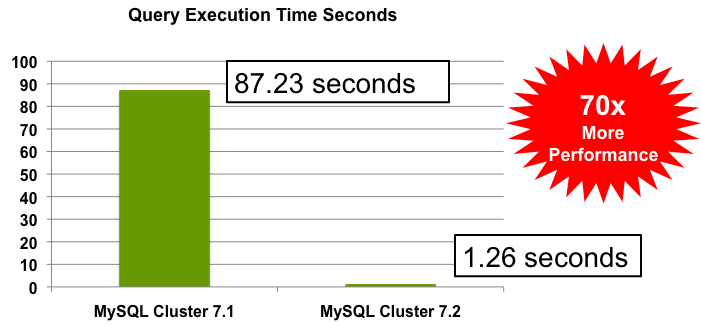
Figure 1: AQL accelerated query performance by 70x
Adaptive Query Localization enables MySQL Cluster to better serve those use-cases that have the need to run real-time analytics across live data sets, along with high throughput OLTP operations. Examples include recommendations engines and clickstream analysis in web applications, pre-pay billing promotions in mobile telecoms networks or fraud detection in payment systems.
New NoSQL Interface and Schema-less Storage with the Memcached API
Today, many websites use InnoDB for OLTP with Memcached as a caching layer to reduce latency and increase performance. But, Memcached is not ACID and the application is responsible for ensuring that the cached data is consistent with the database of record.
Now, you can combine the ease of use of Memcached, with the power of MySQL Cluster. Using the standard Memcached API, the application sends reads and writes to the Memcached process, which in turn invokes the Memcached Driver for NDB (which is part of the same process). This calls the NDB API, providing very quick access to the data held in MySQL Cluster's data nodes, completely bypassing the SQL layer.
The solution has been designed to be very flexible, allowing the application architect to find a configuration that best fits their needs. It is possible to co-locate the Memcached API in either the data nodes or application nodes, or alternatively within a dedicated Memcached layer.
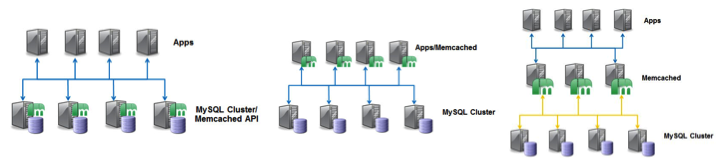
Figure 2: NoSQL Interface and Schema-less Storage with the Memcached API
Developers can still have some or all of the data cached within the Memcached server (and specify whether that data should also be persisted in MySQL Cluster) - so it is possible to choose how to treat different pieces of data, for example:
- Storing the data purely in MySQL Cluster is best for data that is volatile, i.e. written to and read from frequently;
- Storing the data both in MySQL Cluster and in Memcached is often the best option for data that is rarely updated but frequently read;
- Data that has a short lifetime, is read frequently and does not need to be persistent could be stored only in Memcached.
The benefit of this flexible approach to deployment is that users can configure behavior on a per-key-prefix basis (through tables in MySQL Cluster) and the application doesn't have to care - it just uses the Memcached API and relies on the software to store data in the right place(s) and to keep everything synchronized.
MySQL Cluster as a Schema-less Key/Value store
The popularity of Key/Value stores has been increasing. With MySQL Cluster, you have all the benefits of an ACID RDBMS, combined with the performance capabilities and schema flexibility of a Key/Value store.
By default, every Key/Value is written to the same table with each Key/Value pair stored in a single row - thus allowing schema-less data storage. Alternatively, the developer can define a key-prefix so that each value is linked to a pre-defined column in a specific table.
Of course if the application needs to access the same data through SQL then developers can map key prefixes to existing table columns, enabling Memcached access to schema-structured data already stored in MySQL Cluster.
Refer to the MySQL Cluster 7.2 New Features whitepaper to learn more.
Integration with MySQL 5.5
MySQL Cluster 7.2 is integrated with MySQL Server 5.5, providing binary compatibility to existing MySQL Server deployments. Users can now fully exploit the latest capabilities of both the InnoDB and MySQL Cluster storage engines within a single application.
Users simply install the new MySQL Cluster binary including the MySQL 5.5 release, restart the server and immediate have access to both InnoDB and MySQL Cluster!
Auto-Sharding and Auto-Failover Between Data Centers: Multi-Site Clustering
Multi-Site Clustering provides a new option for cross data center scalability. For the first time splitting data nodes across data centers is a supported deployment option. With this deployment model, tables are automatically sharded across sites with synchronous replication between them. Failovers between sites are handled automatically by MySQL Cluster.
Improvements to the heart beating mechanism used by MySQL Cluster enables greater resilience to temporary latency spikes on a WAN, thereby maintaining operation of the cluster.
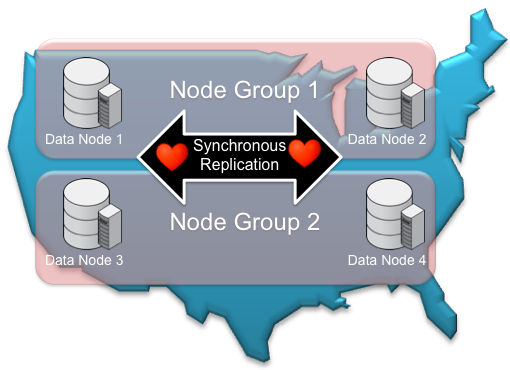
Figure 3: Multi-site clustering enables auto-sharding and failover between data centers
You can read more about the implementation of Multi-Site Clustering in the blog post: Synchronous Replicating Between Data Centers.
Enhancing Cross Data Center Scalability: Simplified Active / Active Replication with Eventual Consistency
MySQL Cluster has long offered asynchronous Geographic Replication, distributing clusters to remote data centers to reduce the affects of geographic latency and providing disaster recovery.
Geographic replication has always been designed around an Active / Active technology, so if applications are attempting to update the same row on different clusters at the same time, the conflict can be detected and resolved. This ensures each site can actively serve read and write requests while maintaining data consistency across the clusters. It also eliminated the overhead of having to provision hardware at remote sites for Disaster Recovery, only to have that hardware sitting idle the vast majority of the time.
With the release of MySQL Cluster 7.2, implementing Active / Active replication has become significantly simpler. Developers no longer need to implement and manage timestamp columns within their applications. Also rollbacks can be made to whole transactions (and subsequent, dependent transactions) rather than just individual operations.
These enhancements make it much simpler to deploy globally scaled services across data centers.
You can read more about the implementation of Eventual Consistency and enhancements to Active/Active replication in the blog post: Enhanced conflict resolution with MySQL Cluster active-active replication.
Improved Ease-of-Use: User Privilege Consolidation
User privilege tables can now be consolidated into the data nodes and centrally accessible by all MySQL servers accessing the cluster.
Previously the privilege tables were local to each MySQL server, meaning users and their associated privileges had to be managed separately on each server. By consolidating privilege data, users need only be defined once and managed centrally, saving Systems Administrators significant effort and reducing cost of operations.
You can read more about the implementation of Consolidated User Privileges in the blog post: Sharing user credentials between MySQL Servers with Cluster.
Improved Ease-of-Use: MySQL Cluster Manager
Oracle has also announced the General Availability of the latest MySQL Cluster Manager release, version 1.1.4, further improving the automation and administration of MySQL Cluster operations, including the ability to provision an entire cluster in a single command.
Download the MySQL Cluster Manager whitepaper »
MySQL Cluster Manager simplifies the creation and management of the MySQL Cluster database by automating common management tasks.
By using MySQL Cluster Manager, Developers and Database Administrators (DBAs) are more productive, enabling them to focus on strategic IT initiatives and respond more quickly to changing user requirements. At the same time, risks of database downtime that previously resulted from manual configuration errors, are significantly reduced.
Download the MySQL Cluster Manager whitepaper »
Summary
MySQL Cluster 7.2 is the best release to date, enabling projects and applications to benefit from web-scalability with carrier-grade availability and developer agility.
If you are considering MySQL Cluster for your next project, download the new Evaluation Guide for best practices in building a Proof of Concept.
You can review the MySQL Cluster documentation, and also ask questions to the MySQL Cluster development team and community via The MySQL Cluster Forum.
We look forward to helping you in your new projects, and working with you to continue evolving MySQL Cluster to serve an even broader set of requirements in the future.